

Что в ORM тебе моем? Околонаучный подход выбора ORM для Android
Выбор инструментов, которые так или иначе понадобятся при
разработке – один из главных подготовительных этапов на старте нового
Android-проекта.
В случае, если вы разрабатываете приложение, которое должно в том или ином виде хранить большое количество сущностей – вам не избежать использования баз данных. В отличие от коллег по цеху, разрабатывающих для iOS, у Android-программистов нет удобных инструментов, облегчающих хранение объектов вроде Core Data, предоставляемых платформой (кроме Content Provider, о том почему он не в счет, будет дальше). Поэтому многие Android-разработчики прибегают к использованию сторонних ORM-решений в своих проектах. О том, на что стоит смотреть при выборе библиотеки для вашего проекта, и пойдет речь в этой статье.

Для начала хотелось бы убедиться, что выбор ORM не надуман и мы рассмотрели все доступные средства для хранения данных, которые предоставляются Android SDK “из коробки”.
Рассмотрим их по мере возрастания сложности написания реализации такого хранилища. Заметьте, что я специально не стал рассматривать обычные файлы в этом сравнении. Они, конечно, являются идеальным вариантом для любителей собственных велосипедов, живущих по философии Not Invented Here, но в нашем случае они будут слишком низкоуровневыми.
Shared Preferences
http://developer.android.com/guide/topics/data/data-storage.html#pref
Хранилище типа ключ-значение для примитивных типов данных. Поддерживаются
Integer, Long, Float, Boolean, String и StringSet. Основное назначение – хранение некоего состояния приложения и пользовательских настроек. По своей сути представляет обертку над XML файлом, который находится в “приватной” папке вашего приложения в поддиректории shared-prefs. Для хранения множества однотипных структурированных данных не подходит.
Базы данных SQLite
http://developer.android.com/guide/topics/data/data-storage.html#db
SQLite является стандартной базой данных в Android. В фреймворке предоставлены несколько классов-помощников, облегчающих работу с базой: SQLiteOpenHelper, ContentValues и т.д. Однако, даже использование этих помощников не избавит вас от обязанности писать огромное количество шаблонного кода, самостоятельно следить за созданием и изменением таблиц, создавать методы для операций, методы для поиска и т.д. Таким образом, код приложений, использующих только стандартные инструменты для работы с SQLite в Android, становится все труднее поддерживать при добавлении новых и изменении старых сущностей.
Content Provider
http://developer.android.com/guide/topics/providers/content-providers.html
Content Provider является прослойкой над реальным хранилищем данных. Может показаться, что Content Provider является “коробочной” реализацией технологии ORM, однако это далеко не так. Если вы используете SQLite в качестве хранилища для Content Provider, вам придется самостоятельно реализовать логику создания, обновления таблиц и базовых CRUD операций. В большинстве случаев использование Content Provider без специальных генераторов не только не сэкономит время на разработке и поддержке, но, возможно, и потратит его куда больше, чем написание своей реализации SQLiteOpenHelper. Однако, Content Provider позволяет использовать некоторые удобные классы платформы – такие как AsyncQueryHandler, CursorLoader, SyncAdapter и другие.
Убеждаемся, что мы рассмотрели все доступные в Android SDK инструменты хранения данных и приходим к выводу: SQLite обеспечивает все необходимые условия для организации хранилища однотипных структурированных данных (удивительно, не правда ли?). Однако, как говорилось выше, использование SQLite в Android требует большого количества кода и постоянной поддержки, поэтому попытаемся облегчить свою жизнь, прибегнув к стороннему решению.
Здесь на помощь как раз и приходит техника ORM — Object Relational Mapping. Ее реализация, по сути, создает впечатление объектной базы данных, имея в своей основе обычную реляционную базу данных. ORM, предоставляя более высокий уровень абстракции, призвано избавить программистов от необходимости конвертировать объекты модели данных в скалярные величины, поддерживаемые базой данных, позволить им писать меньше шаблонного кода и не беспокоиться о структуре таблиц.
Определившись с технологией, обратимся с таким вопросом в интернет и выберем 4 библиотеки:
Как выбрать нужную библиотеку и не пожалеть о своем решении, если будет поздно? В аналогичных статьях я наткнулся только на качественные сравнения библиотек. Однако, на мой взгляд, ORM-библиотека должна быть сбалансирована в плане удобства и производительности. Поэтому сравнение этих решений только с точки зрения API, без анализа производительности, было бы неполным. Но для начала небольшое отступление о том, почему все же стоит обращать внимание на производительность ORM.
Зачем оценивать производительность ORM? Очевидно же, что в конечном счете все упрется в ограничение самой SQLite, а та, в свою очередь, в ограничение файловой системы (речь идет о single-file базе данных). Однако, как выяснилось, до этих естественных ограничений еще очень далеко.
Перед тем, как перейти к описанию проведенного мною теста и его результатам, хотелось бы рассказать небольшую историю о том, почему мы стали обращать внимание на производительность ORM, которую используем в своих проектах и попытках ее улучшить.
Однажды к нам в Sebbia поступило на разработку некое приложение, потребляющее унифицированное для всех клиентов REST API. Из всех существующих на рынке ORM было решено использовать проверенный временем и полностью нас удовлетворяющий на тот момент ActiveAndroid. Основной сущностью приложения (для простоты назовем ее “Сущность”) является некое состояние множества других сущностей системы, части которых (“Владельцы сущности”) были представлены только идентификаторами этих сущностей. Предполагалось, что при запросе “Сущности” клиент будет загружать “Владельцев сущности” автоматически, если они не были обнаружены в кэше приложения. В мобильных устройствах такой ситуации хотелось бы избежать – в виду расходов энергии на отправку нового запроса. Какие-либо изменения в API привели бы к потенциальным проблемам совместимости с другими клиентами. Поэтому мы решили загружать и кэшировать список “Владельцев сущности” до того, как возникнет необходимость загружать сами “Сущности”. Логичнее всего такую операцию выполнять при первом запуске приложения. Стоит оговориться, что список всех “Владельцев сущности” отдавался полностью, а не постранично. Каким же было наше удивление, когда мы увидели то как долго сохраняется этот список в базу данных!
Проверив код еще раз и убедившись, что список сохраняется один раз и внутри транзакции, под наше подозрение попал ActiveAndroid. В общем, причиной падения производительности приложения при сохранении объемного списка была рефлексия, а именно – получение значений полей объекта и заполнение ими ContentValues. Заменив код, использующий рефлексию, на код, сгенерированный самописным плагином для Eclipse, мы получили почти двухкратный прирост производительности – c ~38-ми секунд до 20-ти. Убедившись лишний раз в том, что стоит внимательнее смотреть на то, как устроены open-source библиотеки изнутри, перейдем к содержательной части статьи.
Из всех выбранных библиотек особняком стоит GreenDao – ведь он единственный среди представленных решений, кто использует кодогенерацию. Чтобы не делать быстрых выводов – GreenDao быстрее всех, а про остальные забудьте, мы решили оформить подход с кодогенерацией (использованный в описанном выше проекте в ActiveAndroid) в виде отдельного форка и pull request в официальный репозиторий, параллельно дополнив его другими полезными функциями: поддержкой отношений “одно к многому”, “многое к многому” и автоматической миграции данных при смене структуры сущностей и, соответственно, их таблиц. Полученный форк, который для простоты я буду называть “ActiveAndroid.Sebbia”, был добавлен к тесту.
Настало время рассказать о проведенном тесте. Он проверяет, как быстро та или иная библиотека может сохранять тестовые сущности в ходе SQLite транзакции и совершает обратную операцию. В новосозданную базу данных добавляются 1000 тестовых объектов, которые после очищения кэша в памяти ORM считываются и проверяются на “корректность” данных. Каждый испытуемый проверяется 10 раз, за конечный результат берется среднее время выполнения. Тестовые объекты состоят из двух текстовых полей фиксированной длины, одного поля даты и одного массива байт, полученного из сериализуемого объекта. Изначально предполагалось, что ORM должна была сама преобразовывать Serializable объект в массив байт, но оказалось, что ни у GreenDao, ни у SugarORM нет такой возможности, поэтому от этой идеи пришлось отказаться.
Для того, чтобы понять максимально возможную скорость операции “объект-строка в таблице-объект”, которой можно достичь с помощью стандартных средств Android SDK, в сравнение был добавлен пример использующий SQLiteOpenHelper и скомпилированные SQLiteStatement. Сам проект и все библиотеки версий, на основе которых было произведено сравнение, расположен на GitHub.
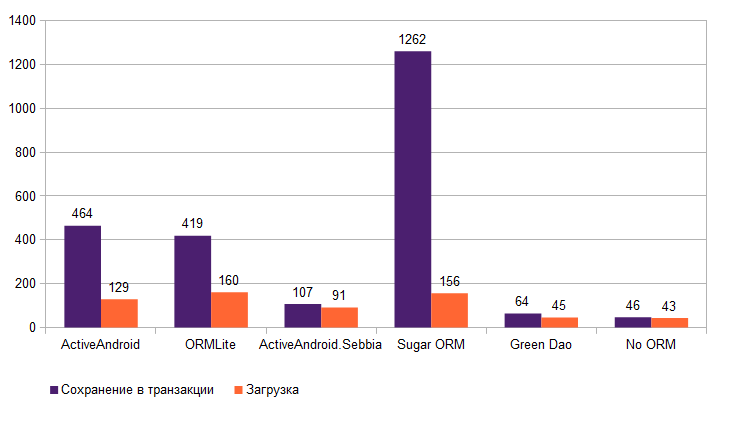
Результаты достаточно предсказуемы, No ORM-решение быстрее всех, хотя опережает оно GreenDAO совсем не на много. По большому счету, код этих решений одинаков, за исключением того, что GreenDAO предоставляет более удобный интерфейс.
В свою очередь, GreenDAO занимает второе место в общем зачете, но первое среди ORM. И это неудивительно. GreenDAO – единственное ORM, полностью использующее кодогенерацию, скомпилированные SQLiteStatement’ы и другие оптимизации.
На второе место среди ORM и третье в общем зачете выходит ActiveAndroid.Sebbia – наш форк ActiveAndroid, использующий кодогенерацию, работающую через Annotation Processor, и SQLiteStatement. Операция записи выполнилась почти в 4 раза быстрее по сравнению с оригинальным проектом, однако чтение удалось оптимизировать незначительно.
ActiveAndroid в зачете ORM третий, затем следует ORMLite-ORM, пришедшая в Android-мир из “большой” Java, имеющая несколько плагинов для работы с разными источниками данных и достаточно удобная в работе. На последнем месте находится SugarORM – самая, на мой взгляд, неудачная из рассмотренных. Во первых, последняя доступная версия из master-ветки не поддерживала сохранение массива байт, пришлось исправить это недоразумение и пересобрать библиотеку, причем на GitHub’e проекта уже давно находится pull request, добавляющий это функцию. Во вторых, SugarORM создает впечатление очень сильно урезанного в функциональном плане клона ActiveAndroid (отсутствие возможности конвертировать объекты других классов и адаптеров).
Хорошо, с производительностью разобрались – кодогенерация быстро, рефлексия медленно. Вызов SQliteDatabase.insert(...) медленнее чем вызов заранее созданного SQLiteStatement. Но насколько, все же, удобно использовать эти библиотеки? Остановимся на каждой подробнее.
Начну я обзор API представленных библиотек с чемпиона – GreenDAO.
Как уже говорилось выше, проект довольно необычен по сравнению с остальными ORM. Вместо того, чтобы создавать классы сущностей самостоятельно и указывать поля, хранящиеся в таблице, GreenDAO предлагает составлять эти классы из другого кода, полученный код генерации необходимо запускать как обычное Java приложение. Вот как примерно это выглядит:
Если вам необходимо добавить свои поля в классе сущности, вам необходимо поместить их в блоки, отмеченные специальными комментариями:
Аналогичные блоки комментариев предусмотрены и для методов, и для импорта. Если не принимать во внимание ошеломляющую производительность такого подхода, то его удобство крайне сомнительно, особенно если использовать GreenDAO с первого дня разработки. Однако вопросы возникают и при использовании уже сгенерированного кода. Например, зачем нужно писать столько, чтобы получить DAO объект:
Мне кажется, что это чересчур. Понятно, что создавать DaoMaster каждый раз не понадобится, но все же. Итак, с GreenDAO вам придется выполнять лишние телодвижения для поддержки кода и использовать не самое удачное API. Однако взамен вы получаете скорость и приятные бонусы вроде поддержки Protobuf объектов из коробки.
Перейдем к ORMLite. ORMLite предлагает активно использовать аннотации при объявлении своих сущностей:
Через аннотации можно задать и тип данных поля, что очень удобно и не размазывает код, связанный с моделью по проекту. Проект поддерживает множество типов данных и вариантов их хранения. Например, для java.util.Date предусмотрен как числовой, так и строковый вариант. К недостаткам можно отнести необходимость реализовывать OrmLiteSqliteOpenHelper, через который вы сможете получить DAO объект и взаимодействовать с ORM. Использование отдельных DAO объектов избавляет от необходимости наследовать классы ваших сущностей от объектов сторонних библиотек и позволяет гибко управлять кэшем.
ActiveAndroid использует схожий подход с аннотациями, однако требует, чтобы классы модели наследовались от предоставляемого им класса Model. На мой взгляд, такое решение оптимально по удобству только если ваши сущности уже не наследуются от какого-либо класса, родителя которого вы не можете изменить. Такое наследование позволять иметь удобные методы типа save() и delete() у объектов модели без создания дополнительных DAO объектов. В библиотеке также предоставлены сериализаторы дат BigDecimal и других типов, а для сериализации полей нестандартных типов достаточно реализовать свой TypeSerializer и указать его при инициализации.
Как уже говорилось выше, Sugar ORM создает впечатление достаточно слабого клона ActiveAndroid. Однако Sugar ORM не требует наследования от какого-либо абстрактного класса и имеет достаточно лаконичное API:
ActiveAndroid.Sebbia представляет собой форк ActiveAndroid с поддержкой кодогенерации. В этом проекте генерация кода связывания SQLiteStatement и Cursor с объектом сущности происходит с помощью Annotation Processor. Использование Annotation Processor вместо плагина для IDE позволяет применять его как в Eclipse и в IntelliJ IDEA, так и при сборке проекта с помощью Gradle или Ant. Однако, это накладывает некоторое ограничение на видимость полей классов модели: минимальная допустимая видимость в этом случае будет без модификатора (default). Кодогенерация позволила добиться примерно 30% прироста производительности, все остальное – заслуга заранее скомпилированного SQLiteStatement. Также, этот форк содержит OneToManyRelation, ManyToManyRelation и поддержку автоматических миграций, которая используется, когда не найден SQL-скрипт миграции для текущей версии.
В заключении хотелось бы подвести итог нашему небольшому исследованию. ORM – это полезный инструмент, который поможет вам сохранить время при разработке ваших приложений. И он абсолютно незаменим в случае модели с множеством сущностей и взаимосвязей между ними.
Стоит помнить, что в реальной жизни конечный пользователь, скорее всего, не увидит никакой разницы между самым быстрым и самым медленным ORM, поэтому стоит ли задумываться на этот счет – выбор каждого. Остается добавить, что решение, которое вы выберете, должно быть удобным и отвечать вашим требованиям. В любом случае, следует придерживаться общих правил при выборе open-source библиотек в ваших проектах, а именно – оценивать, какие известные приложения используют, какое качество исходного кода и как она работает изнутри.
Ссылки на репозитории:
Проект-бенчмарк
ActiveAndroid.Sebbia
developer.android.com/guide/topics/data/data-storage.html
2. Object-relational mapping
en.wikipedia.org/wiki/Object-relational_mapping
3. Java Reflection Performance
stackoverflow.com/q/435553/2287859
4. Is Java Reflection Slow?
vaskoz.wordpress.com/2013/07/15/is-java-reflection-slow/
5. Comparing android ORM libraries — GreenDAO vs Ormlite
software-workshop.eu/content/comparing-android-orm-libraries-greendao-vs-ormlite
6. 5 of the Best Android ORMs
www.sitepoint.com/5-best-android-orms/
7. Android Orm Benchmark
github.com/littleinc/android-orm-benchmark
В случае, если вы разрабатываете приложение, которое должно в том или ином виде хранить большое количество сущностей – вам не избежать использования баз данных. В отличие от коллег по цеху, разрабатывающих для iOS, у Android-программистов нет удобных инструментов, облегчающих хранение объектов вроде Core Data, предоставляемых платформой (кроме Content Provider, о том почему он не в счет, будет дальше). Поэтому многие Android-разработчики прибегают к использованию сторонних ORM-решений в своих проектах. О том, на что стоит смотреть при выборе библиотеки для вашего проекта, и пойдет речь в этой статье.
Для начала хотелось бы убедиться, что выбор ORM не надуман и мы рассмотрели все доступные средства для хранения данных, которые предоставляются Android SDK “из коробки”.
Рассмотрим их по мере возрастания сложности написания реализации такого хранилища. Заметьте, что я специально не стал рассматривать обычные файлы в этом сравнении. Они, конечно, являются идеальным вариантом для любителей собственных велосипедов, живущих по философии Not Invented Here, но в нашем случае они будут слишком низкоуровневыми.
Shared Preferences
http://developer.android.com/guide/topics/data/data-storage.html#pref
Хранилище типа ключ-значение для примитивных типов данных. Поддерживаются
Integer, Long, Float, Boolean, String и StringSet. Основное назначение – хранение некоего состояния приложения и пользовательских настроек. По своей сути представляет обертку над XML файлом, который находится в “приватной” папке вашего приложения в поддиректории shared-prefs. Для хранения множества однотипных структурированных данных не подходит.
Базы данных SQLite
http://developer.android.com/guide/topics/data/data-storage.html#db
SQLite является стандартной базой данных в Android. В фреймворке предоставлены несколько классов-помощников, облегчающих работу с базой: SQLiteOpenHelper, ContentValues и т.д. Однако, даже использование этих помощников не избавит вас от обязанности писать огромное количество шаблонного кода, самостоятельно следить за созданием и изменением таблиц, создавать методы для операций, методы для поиска и т.д. Таким образом, код приложений, использующих только стандартные инструменты для работы с SQLite в Android, становится все труднее поддерживать при добавлении новых и изменении старых сущностей.
Content Provider
http://developer.android.com/guide/topics/providers/content-providers.html
Content Provider является прослойкой над реальным хранилищем данных. Может показаться, что Content Provider является “коробочной” реализацией технологии ORM, однако это далеко не так. Если вы используете SQLite в качестве хранилища для Content Provider, вам придется самостоятельно реализовать логику создания, обновления таблиц и базовых CRUD операций. В большинстве случаев использование Content Provider без специальных генераторов не только не сэкономит время на разработке и поддержке, но, возможно, и потратит его куда больше, чем написание своей реализации SQLiteOpenHelper. Однако, Content Provider позволяет использовать некоторые удобные классы платформы – такие как AsyncQueryHandler, CursorLoader, SyncAdapter и другие.
Убеждаемся, что мы рассмотрели все доступные в Android SDK инструменты хранения данных и приходим к выводу: SQLite обеспечивает все необходимые условия для организации хранилища однотипных структурированных данных (удивительно, не правда ли?). Однако, как говорилось выше, использование SQLite в Android требует большого количества кода и постоянной поддержки, поэтому попытаемся облегчить свою жизнь, прибегнув к стороннему решению.
Здесь на помощь как раз и приходит техника ORM — Object Relational Mapping. Ее реализация, по сути, создает впечатление объектной базы данных, имея в своей основе обычную реляционную базу данных. ORM, предоставляя более высокий уровень абстракции, призвано избавить программистов от необходимости конвертировать объекты модели данных в скалярные величины, поддерживаемые базой данных, позволить им писать меньше шаблонного кода и не беспокоиться о структуре таблиц.
Определившись с технологией, обратимся с таким вопросом в интернет и выберем 4 библиотеки:
Как выбрать нужную библиотеку и не пожалеть о своем решении, если будет поздно? В аналогичных статьях я наткнулся только на качественные сравнения библиотек. Однако, на мой взгляд, ORM-библиотека должна быть сбалансирована в плане удобства и производительности. Поэтому сравнение этих решений только с точки зрения API, без анализа производительности, было бы неполным. Но для начала небольшое отступление о том, почему все же стоит обращать внимание на производительность ORM.
Зачем все это?
Зачем оценивать производительность ORM? Очевидно же, что в конечном счете все упрется в ограничение самой SQLite, а та, в свою очередь, в ограничение файловой системы (речь идет о single-file базе данных). Однако, как выяснилось, до этих естественных ограничений еще очень далеко.
Перед тем, как перейти к описанию проведенного мною теста и его результатам, хотелось бы рассказать небольшую историю о том, почему мы стали обращать внимание на производительность ORM, которую используем в своих проектах и попытках ее улучшить.
Однажды к нам в Sebbia поступило на разработку некое приложение, потребляющее унифицированное для всех клиентов REST API. Из всех существующих на рынке ORM было решено использовать проверенный временем и полностью нас удовлетворяющий на тот момент ActiveAndroid. Основной сущностью приложения (для простоты назовем ее “Сущность”) является некое состояние множества других сущностей системы, части которых (“Владельцы сущности”) были представлены только идентификаторами этих сущностей. Предполагалось, что при запросе “Сущности” клиент будет загружать “Владельцев сущности” автоматически, если они не были обнаружены в кэше приложения. В мобильных устройствах такой ситуации хотелось бы избежать – в виду расходов энергии на отправку нового запроса. Какие-либо изменения в API привели бы к потенциальным проблемам совместимости с другими клиентами. Поэтому мы решили загружать и кэшировать список “Владельцев сущности” до того, как возникнет необходимость загружать сами “Сущности”. Логичнее всего такую операцию выполнять при первом запуске приложения. Стоит оговориться, что список всех “Владельцев сущности” отдавался полностью, а не постранично. Каким же было наше удивление, когда мы увидели то как долго сохраняется этот список в базу данных!
Проверив код еще раз и убедившись, что список сохраняется один раз и внутри транзакции, под наше подозрение попал ActiveAndroid. В общем, причиной падения производительности приложения при сохранении объемного списка была рефлексия, а именно – получение значений полей объекта и заполнение ими ContentValues. Заменив код, использующий рефлексию, на код, сгенерированный самописным плагином для Eclipse, мы получили почти двухкратный прирост производительности – c ~38-ми секунд до 20-ти. Убедившись лишний раз в том, что стоит внимательнее смотреть на то, как устроены open-source библиотеки изнутри, перейдем к содержательной части статьи.
Гонка вооружений
Из всех выбранных библиотек особняком стоит GreenDao – ведь он единственный среди представленных решений, кто использует кодогенерацию. Чтобы не делать быстрых выводов – GreenDao быстрее всех, а про остальные забудьте, мы решили оформить подход с кодогенерацией (использованный в описанном выше проекте в ActiveAndroid) в виде отдельного форка и pull request в официальный репозиторий, параллельно дополнив его другими полезными функциями: поддержкой отношений “одно к многому”, “многое к многому” и автоматической миграции данных при смене структуры сущностей и, соответственно, их таблиц. Полученный форк, который для простоты я буду называть “ActiveAndroid.Sebbia”, был добавлен к тесту.
Настало время рассказать о проведенном тесте. Он проверяет, как быстро та или иная библиотека может сохранять тестовые сущности в ходе SQLite транзакции и совершает обратную операцию. В новосозданную базу данных добавляются 1000 тестовых объектов, которые после очищения кэша в памяти ORM считываются и проверяются на “корректность” данных. Каждый испытуемый проверяется 10 раз, за конечный результат берется среднее время выполнения. Тестовые объекты состоят из двух текстовых полей фиксированной длины, одного поля даты и одного массива байт, полученного из сериализуемого объекта. Изначально предполагалось, что ORM должна была сама преобразовывать Serializable объект в массив байт, но оказалось, что ни у GreenDao, ни у SugarORM нет такой возможности, поэтому от этой идеи пришлось отказаться.
Для того, чтобы понять максимально возможную скорость операции “объект-строка в таблице-объект”, которой можно достичь с помощью стандартных средств Android SDK, в сравнение был добавлен пример использующий SQLiteOpenHelper и скомпилированные SQLiteStatement. Сам проект и все библиотеки версий, на основе которых было произведено сравнение, расположен на GitHub.
Результаты достаточно предсказуемы, No ORM-решение быстрее всех, хотя опережает оно GreenDAO совсем не на много. По большому счету, код этих решений одинаков, за исключением того, что GreenDAO предоставляет более удобный интерфейс.
В свою очередь, GreenDAO занимает второе место в общем зачете, но первое среди ORM. И это неудивительно. GreenDAO – единственное ORM, полностью использующее кодогенерацию, скомпилированные SQLiteStatement’ы и другие оптимизации.
На второе место среди ORM и третье в общем зачете выходит ActiveAndroid.Sebbia – наш форк ActiveAndroid, использующий кодогенерацию, работающую через Annotation Processor, и SQLiteStatement. Операция записи выполнилась почти в 4 раза быстрее по сравнению с оригинальным проектом, однако чтение удалось оптимизировать незначительно.
ActiveAndroid в зачете ORM третий, затем следует ORMLite-ORM, пришедшая в Android-мир из “большой” Java, имеющая несколько плагинов для работы с разными источниками данных и достаточно удобная в работе. На последнем месте находится SugarORM – самая, на мой взгляд, неудачная из рассмотренных. Во первых, последняя доступная версия из master-ветки не поддерживала сохранение массива байт, пришлось исправить это недоразумение и пересобрать библиотеку, причем на GitHub’e проекта уже давно находится pull request, добавляющий это функцию. Во вторых, SugarORM создает впечатление очень сильно урезанного в функциональном плане клона ActiveAndroid (отсутствие возможности конвертировать объекты других классов и адаптеров).
Хорошо, с производительностью разобрались – кодогенерация быстро, рефлексия медленно. Вызов SQliteDatabase.insert(...) медленнее чем вызов заранее созданного SQLiteStatement. Но насколько, все же, удобно использовать эти библиотеки? Остановимся на каждой подробнее.
Удобства во дворе
Начну я обзор API представленных библиотек с чемпиона – GreenDAO.
Как уже говорилось выше, проект довольно необычен по сравнению с остальными ORM. Вместо того, чтобы создавать классы сущностей самостоятельно и указывать поля, хранящиеся в таблице, GreenDAO предлагает составлять эти классы из другого кода, полученный код генерации необходимо запускать как обычное Java приложение. Вот как примерно это выглядит:
public static void main(String[] args) throws Exception {
Schema schema = new Schema(1, "com.sebbia.ormbenchmark.greendao");
schema.enableKeepSectionsByDefault();
Entity entity = schema.addEntity("GreenDaoEntity");
entity.implementsInterface("com.sebbia.ormbenchmark.BenchmarkEntity");
entity.addIdProperty().autoincrement();
entity.addStringProperty("field1");
entity.addStringProperty("field2");
entity.addByteArrayProperty("blobArray");
entity.addDateProperty("date");
new DaoGenerator().generateAll(schema, "../src-gen/");
}
Если вам необходимо добавить свои поля в классе сущности, вам необходимо поместить их в блоки, отмеченные специальными комментариями:
// KEEP FIELDS - put your custom fields here
private Blob blob;
// KEEP FIELDS END
Аналогичные блоки комментариев предусмотрены и для методов, и для импорта. Если не принимать во внимание ошеломляющую производительность такого подхода, то его удобство крайне сомнительно, особенно если использовать GreenDAO с первого дня разработки. Однако вопросы возникают и при использовании уже сгенерированного кода. Например, зачем нужно писать столько, чтобы получить DAO объект:
DevOpenHelper devOpenHelper = new DaoMaster.DevOpenHelper(context, "greendao", null);
DaoMaster daoMaster = new DaoMaster(devOpenHelper.getWritableDatabase());
DaoSession daoSession = daoMaster.newSession();
GreenDaoEntityDao dao = daoSession.getGreenDaoEntityDao();
Мне кажется, что это чересчур. Понятно, что создавать DaoMaster каждый раз не понадобится, но все же. Итак, с GreenDAO вам придется выполнять лишние телодвижения для поддержки кода и использовать не самое удачное API. Однако взамен вы получаете скорость и приятные бонусы вроде поддержки Protobuf объектов из коробки.
Перейдем к ORMLite. ORMLite предлагает активно использовать аннотации при объявлении своих сущностей:
@DatabaseTable(tableName = "entity")
public class OrmLiteEntity implements BenchmarkEntity {
@DatabaseField(columnName = "id", generatedId = true)
private long id;
@DatabaseField(columnName = "field1")
private String field1;
@DatabaseField(columnName = "field2")
private String field2;
@DatabaseField(columnName = "blob", dataType = DataType.BYTE_ARRAY)
private byte[] blobArray;
@DatabaseField(columnName = "date", dataType = DataType.DATE)
private Date date;
}
Через аннотации можно задать и тип данных поля, что очень удобно и не размазывает код, связанный с моделью по проекту. Проект поддерживает множество типов данных и вариантов их хранения. Например, для java.util.Date предусмотрен как числовой, так и строковый вариант. К недостаткам можно отнести необходимость реализовывать OrmLiteSqliteOpenHelper, через который вы сможете получить DAO объект и взаимодействовать с ORM. Использование отдельных DAO объектов избавляет от необходимости наследовать классы ваших сущностей от объектов сторонних библиотек и позволяет гибко управлять кэшем.
ActiveAndroid использует схожий подход с аннотациями, однако требует, чтобы классы модели наследовались от предоставляемого им класса Model. На мой взгляд, такое решение оптимально по удобству только если ваши сущности уже не наследуются от какого-либо класса, родителя которого вы не можете изменить. Такое наследование позволять иметь удобные методы типа save() и delete() у объектов модели без создания дополнительных DAO объектов. В библиотеке также предоставлены сериализаторы дат BigDecimal и других типов, а для сериализации полей нестандартных типов достаточно реализовать свой TypeSerializer и указать его при инициализации.
Как уже говорилось выше, Sugar ORM создает впечатление достаточно слабого клона ActiveAndroid. Однако Sugar ORM не требует наследования от какого-либо абстрактного класса и имеет достаточно лаконичное API:
@Override
public void saveEntitiesInTransaction(final List<SugarOrmEntity> entities) {
SugarRecord.saveInTx(entities);
}
@Override
public List<SugarOrmEntity> loadEntities() {
List<SugarOrmEntity> entities = SugarRecord.listAll(SugarOrmEntity.class);
return entities;
}
ActiveAndroid.Sebbia представляет собой форк ActiveAndroid с поддержкой кодогенерации. В этом проекте генерация кода связывания SQLiteStatement и Cursor с объектом сущности происходит с помощью Annotation Processor. Использование Annotation Processor вместо плагина для IDE позволяет применять его как в Eclipse и в IntelliJ IDEA, так и при сборке проекта с помощью Gradle или Ant. Однако, это накладывает некоторое ограничение на видимость полей классов модели: минимальная допустимая видимость в этом случае будет без модификатора (default). Кодогенерация позволила добиться примерно 30% прироста производительности, все остальное – заслуга заранее скомпилированного SQLiteStatement. Также, этот форк содержит OneToManyRelation, ManyToManyRelation и поддержку автоматических миграций, которая используется, когда не найден SQL-скрипт миграции для текущей версии.
Заключение
В заключении хотелось бы подвести итог нашему небольшому исследованию. ORM – это полезный инструмент, который поможет вам сохранить время при разработке ваших приложений. И он абсолютно незаменим в случае модели с множеством сущностей и взаимосвязей между ними.
Стоит помнить, что в реальной жизни конечный пользователь, скорее всего, не увидит никакой разницы между самым быстрым и самым медленным ORM, поэтому стоит ли задумываться на этот счет – выбор каждого. Остается добавить, что решение, которое вы выберете, должно быть удобным и отвечать вашим требованиям. В любом случае, следует придерживаться общих правил при выборе open-source библиотек в ваших проектах, а именно – оценивать, какие известные приложения используют, какое качество исходного кода и как она работает изнутри.
Ссылки на репозитории:
Проект-бенчмарк
ActiveAndroid.Sebbia
Список литературы
1. Android Storage Options Guidedeveloper.android.com/guide/topics/data/data-storage.html
2. Object-relational mapping
en.wikipedia.org/wiki/Object-relational_mapping
3. Java Reflection Performance
stackoverflow.com/q/435553/2287859
4. Is Java Reflection Slow?
vaskoz.wordpress.com/2013/07/15/is-java-reflection-slow/
5. Comparing android ORM libraries — GreenDAO vs Ormlite
software-workshop.eu/content/comparing-android-orm-libraries-greendao-vs-ormlite
6. 5 of the Best Android ORMs
www.sitepoint.com/5-best-android-orms/
7. Android Orm Benchmark
github.com/littleinc/android-orm-benchmark